Видео с ютуба Token Per Second Benchmarks
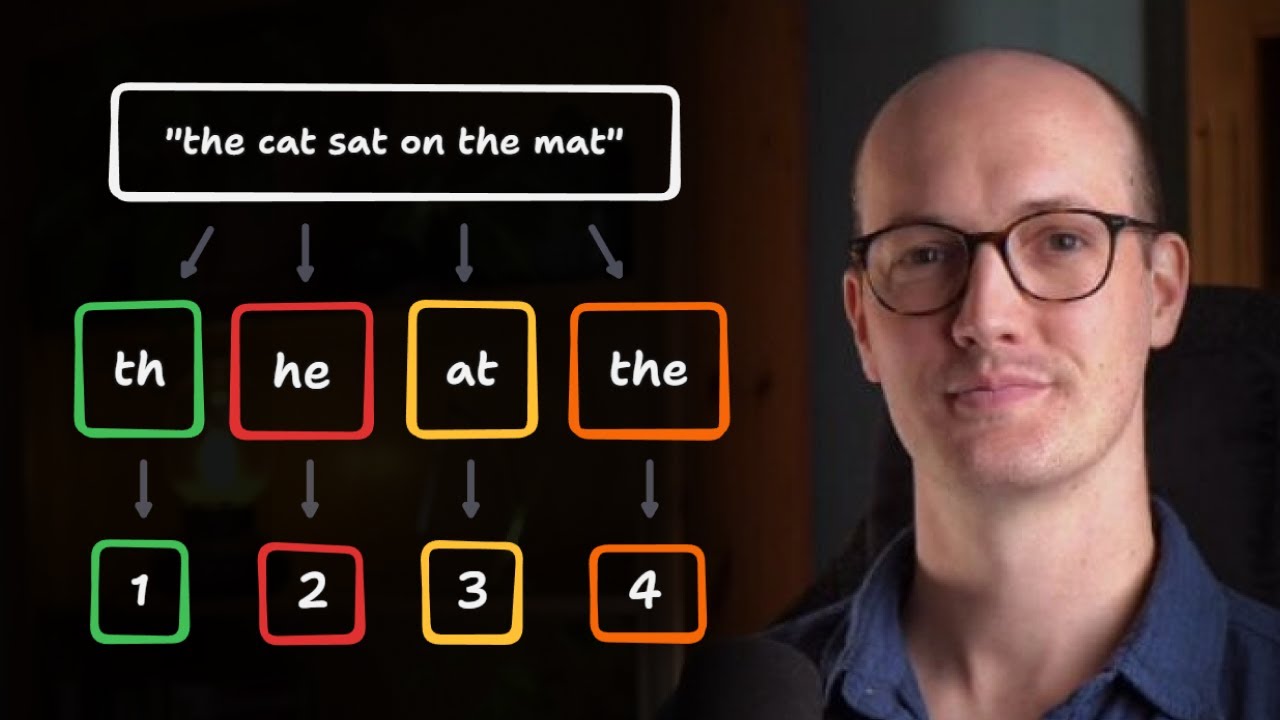
Большинство разработчиков не понимают, как работают токены LLM.
The Token Arbitrage: Groq vs. DeepInfra vs. Cerebras vs fireworks (2025 Benchmark)

Что такое токен ИИ? | Что такое токены LLM за 2 минуты!

THIS is the REAL DEAL 🤯 for local LLMs

New Mercury 2 Breaks The Latency Wall At 1k Tokens per Second (Destroys GPTs)

DeepSeek 70B | Ollama Bench Performance | NVIDIA A100 SXM 80GB | Token Generation Test

I Thought DGX Spark Was Slower… Until I Changed ONE Thing

Nvidia, You’re Late. World’s First 128GB LLM Mini Is Here!

Skip M3 Ultra & RTX 5090 for LLMs | NEW 96GB KING

Same 128GB but cheaper

What is Floating-Point Performance?

Local Ai Server Benchmark 3090 vs Dual 3060s Performance is INSANE!

Chad Smith Hears Thirty Seconds To Mars For The First Time
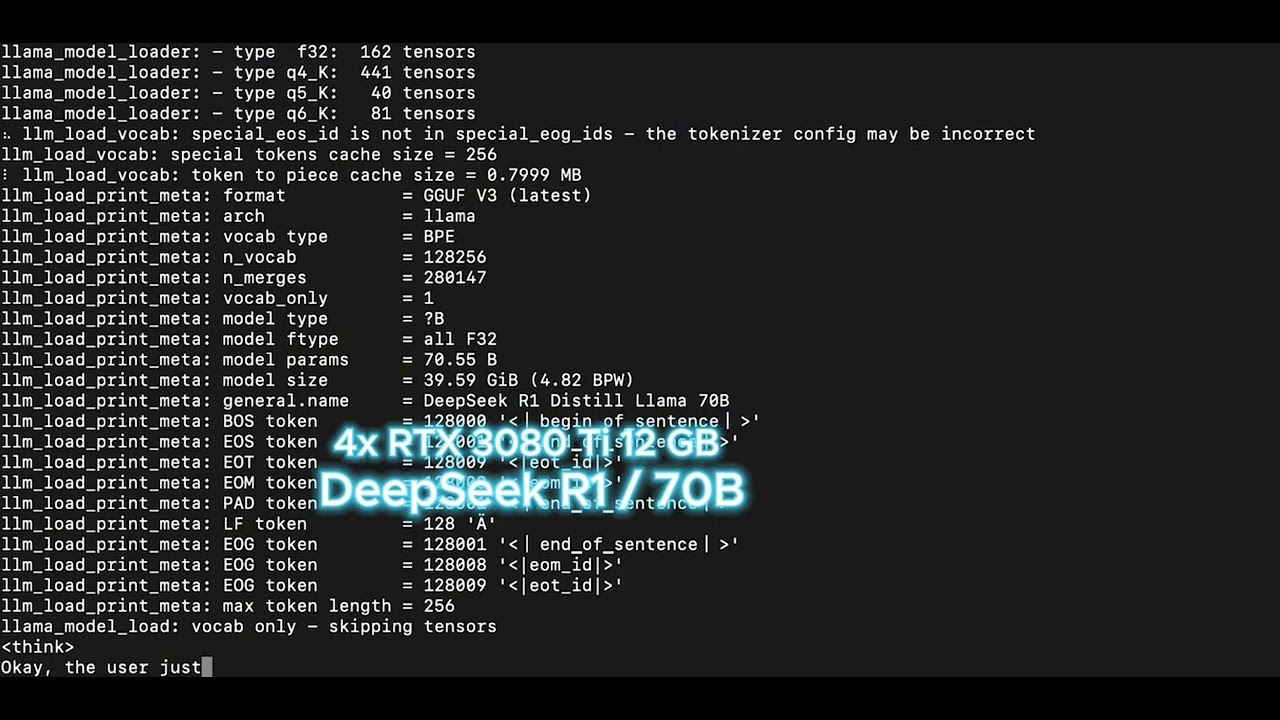
4x RTX 3080 Ti | DeepSeek 70B Model | Ollama Bench Token Generation Performance

External GPU vs PCIe Slot: The LLM Speed Test

Dev Workloads and LLMs… under $1000

Local Ai Budget GPU 9060 XT 16GB vs 5060 Ti 16GB

DGX Spark vs Quad 3090s Local AI Benchmarks - Best Rig for $4K?

Deepseek R1 671b on a $500 AI PC!

RTX 3060 vs RTX 3090: LLM Performance on 7B, 14B, 32B, 70B Models